Temps de lecture estimé 10 minutes.
Nous proposons une série de quelques articles où nous allons utiliser la
bibliothèque Pandas pour analyser les licences sportives en France. En chemin,
nous réaliserons une interface utilisateur avec des widgets.
Cette série sera découpée en trois articles. Dans le premier, nous allons
explorer le jeu de données à notre disposition en utilisant la bibliothèque
Pandas. Dans le second, nous introduirons Jupyter et les ipywidgets qui
nous permettront de faire une interface utilisateur. Nous terminerons la série
en présentant Voilà ainsi que le thème jupyter-flex.
Pandas, jupyter, ipywidgets, voilà ? De quoi parle-t-on ?
- Pandas est une bibliothèque Python très connue,
qui permet d’analyser et d’étudier des jeux de données. Elle est conçue pour
traiter des jeux de données tabulaires (ceux pouvant être lus par un tableur).
Les données peuvent être de différents types (nombres, dates, chaînes de
caractères, etc). Pandas est, comme nous le verrons, très efficace. Les
fonctions coûteuses de Pandas sont généralement écrites en C, et Python est
utilisé pour manipuler et appeler ces fonctions.
- Jupyter est une plateforme, utilisable dans un
navigateur web qui permet d’exécuter des calepins (notebooks). Un calepin
est un fichier qui combine des cellules de différents types : du code
exécutable, du texte, des visualisations, etc.
- Les Ipywidgets sont des
éléments graphiques interactifs que l’on peut ajouter à des calepins
Jupyter. Ils vont nous permettre de proposer aux utilisateurs de choisir un
fichier, choisir un élément dans une liste, cliquer sur un bouton, etc.
Chacune des actions de l’utilisateur peut être associée à une fonction Python,
et donc rendre le calepin interactif.
- Voilà est une application qui
permet d’exécuter des calepins, mais sans afficher le code source − qui est
visible par défaut dans Jupyter. L’énorme intérêt à cela est qu’un calepin
Jupyter devient alors une application web à part entière, utilisable dans le
navigateur, et seuls les éléments indispensables à son utilisation sont
visibles.
Après cette petite phase de présentation, découvrons les données que nous allons
manipuler aujourd’hui.
Présentation des données
Dans cette série d’articles nous utilisons des données issues de
https://data.gouv.fr. Il s’agit du nombre de licences
sportives, par sexe, par catégorie d’âges, par municipalité pour les années 2012
à 2018. Les données brutes peuvent être téléchargées
ici.
Nous avons réalisé une opération de nettoyage sur ces données, afin de nous
assurer d’avoir une structure cohérente pour chaque année. Nous avons également
remplacé les municipalités par leur département, ce qui permet d’alléger les
données à manipuler. Au final, nous obtenons six fichiers csv, un par année,
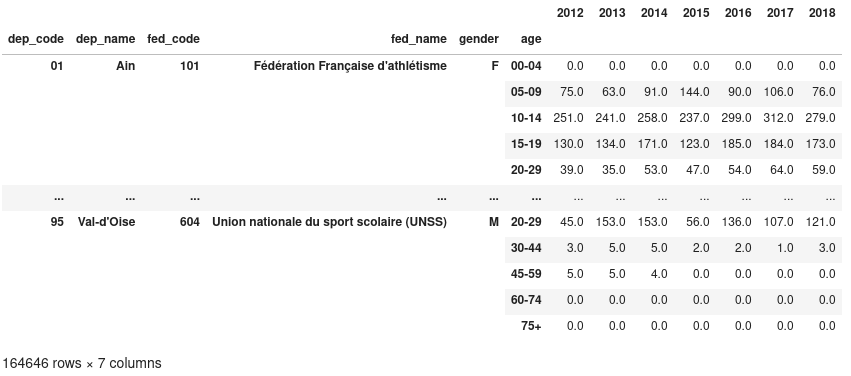
dont la structure est la suivante :
dep_code,dep_name,fed_code,fed_name,gender,age,lic_holders
01,Ain,101,Fédération Française d'athlétisme,F,00-04,0
01,Ain,101,Fédération Française d'athlétisme,F,05-09,75
01,Ain,101,Fédération Française d'athlétisme,F,10-14,251
01,Ain,101,Fédération Française d'athlétisme,F,15-19,130
01,Ain,101,Fédération Française d'athlétisme,F,20-29,39
01,Ain,101,Fédération Française d'athlétisme,F,30-44,105
01,Ain,101,Fédération Française d'athlétisme,F,45-59,105
01,Ain,101,Fédération Française d'athlétisme,F,60-74,23
01,Ain,101,Fédération Française d'athlétisme,F,75+,0
01,Ain,101,Fédération Française d'athlétisme,M,00-04,0
01,Ain,101,Fédération Française d'athlétisme,M,05-09,106
01,Ain,101,Fédération Française d'athlétisme,M,10-14,278
[…]
| Nom de colonne |
Description |
dep_code |
Code (unique) du département |
dep_name |
Nom du département |
fed_code |
Code (unique) de la fédération sportive |
fed_name |
Nom de la fédération sportive |
gender |
Genre (peut être M ou F) |
age |
La tranche d’âge considérée (peut être 00-04, 05-09, 10-14, 15-19, 20-29, 30-44, 44-59, 60-74, 75+) |
lic_holders |
Le nombre de licenciés dans le département, enregistrés dans cette fédération, de ce genre et de cette tranche d’âge. |
Chargement de données pour une année
Pandas offre un nombre important de fonctions permettant de charger des données
depuis différents formats: CSV, Excel, tableaux HTML, JSON, bases SQL, HDF5, etc.
Nous allons utiliser la fonction read_csv. Cette fonction utilise les éléments
de la première ligne comme noms de colonnes. Pandas essaie également de détecter
les types de colonnes à utiliser (nombre, date, chaîne de caractères) en se
basant sur les premiers éléments lus. Nous spécifions donc à Pandas que la
colonne dep_code est de type str, pour prendre en compte les départements
Corse (2A et 2B), sans quoi Pandas émettra un avertissement.
from pathlib import Path
import pandas as pd
DATA_DIR = Path().resolve() / "data" # en supposant que les données sont dans le dossier data
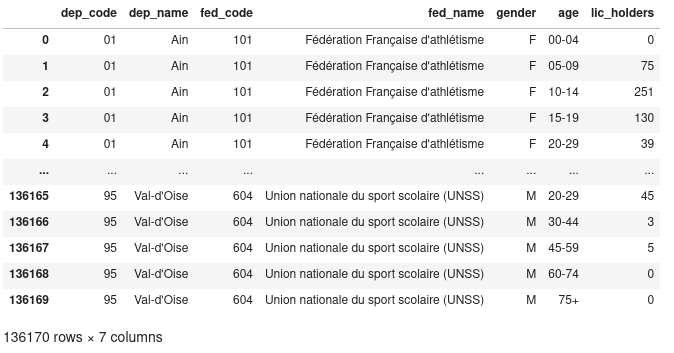
d2012 = pd.read_csv(
DATA_DIR / "sport_license_holders_2012.csv", dtype={"dep_code": str}
)
Nous obtenons alors la DataFrame suivante :
Premières analyses
À partir de là, nous pouvons commencer à étudier le jeu de données. Par exemple,
en demandant le nom de chaque fédération :
>>> d2012["fed_name"].unique()
array(["Fédération Française d'athlétisme",
"Fédération Française des sociétés d'aviron",
'Fédération Française de badminton',
'Fédération Française de basketball',
'Fédération Française de boxe',
'Fédération Française de canoë-kayak',
'Fédération Française de cyclisme',
"Fédération Française d'équitation",
"Fédération Française d'escrime",
[…],
'Fédération française de pentathlon moderne',
'Fédération Française de javelot tir sur cible',
'Fédération Flying Disc France', 'Fédération Française Maccabi',
'Fédération Française de la course camarguaise',
'Fédération Française de la course landaise',
'Fédération Française de ballon au poing'], dtype=object)
Nous pouvons facilement compter le nombre total, toutes catégories
confondues, de licenciés :
>>> d2012["lic_holders"].sum()
12356101
Une des forces de Pandas réside dans la possibilité de créer des filtres, ou des
groupes simplement. Par exemple, pour compter le nombre de licenciés hommes, nous
pouvons créer un masque (True si le genre est M et False sinon), puis
appliquer ce masque à notre DataFrame.
>>> mask_male = d2012["gender"] == "M"
>>> d2012[mask_male]["lic_holders"].sum()
7806235
Ainsi, en 2012, il y avait 7 806 235 licenciés masculins de sport en France.
Combien y a-t-il de licenciés, en 2012, par tranche d’âge ? Pour répondre à
cette question, nous utilisons la méthode groupby de Pandas, en donnant le nom
de la colonne sur laquelle nous souhaitons faire le groupe :
>>> d2012.groupby("age")["lic_holders"].sum()
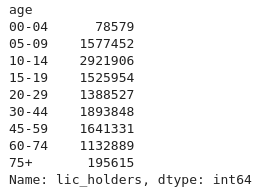
Cette méthode permet de constituer des groupes, selon une clé (généralement le
nom d’une ou plusieurs colonnes), puis d’appliquer sur chaque groupe partageant
la même clé une fonction d’agrégation. Dans notre exemple, la clé de chaque
groupe est l’âge, et la fonction d’agrégation la somme sur la colonne
lic_holders.
Nous pouvons effectuer le même type de calcul, mais en groupant cette fois-ci
sur le genre et l’âge, ce qui donne le résultat suivant :
>>> d2012.groupby(["gender", "age"])["lic_holders"].sum()
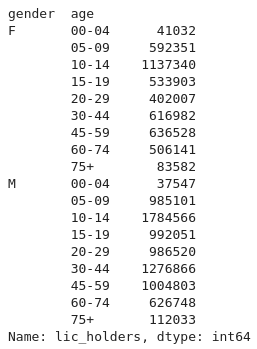
Les deux résultats que nous venons d’obtenir sont ce qu’on appelle des Series.
C’est-à-dire, des DataFrames mais constituées d’une seule colonne.
On observe que les groupes sont directement constitués par l’index. Dans le cas
d’un groupby() avec une seule colonne, nous avons un index simple et dans le
cas où plusieurs colonnes sont utilisées, nous obtenons ce qu’on appelle un
index multiple ou un index hiérarchique. Nous allons étudier cela un peu
plus en profondeur dans la suite.
Créer un index sur mesure
Dans la DataFrame que nous avons chargée, de très nombreuses données sont
répétées et ne sont utilisées que pour définir des groupes (dep_code,
dep_name, gender, age etc). Nous allons mettre toutes ces données dans
l’index de la DataFrame. Cela permet d’avoir dans l’index les données de
chaque groupe, et dans la DataFrame les données desdits groupes (ici le nombre
de licenciés sportifs).
Pour ce faire, nous utilisons la méthode set_index :
>>> d2012.set_index(
["dep_code", "dep_name", "fed_code", "fed_name", "gender", "age"], inplace=True
)
>>> d2012
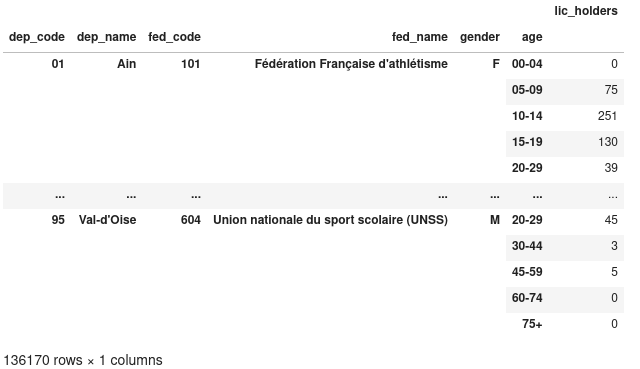
Nous avons ainsi une DataFrame à une seule colonne, et avec un index à six
niveaux. Nous pouvons toujours grouper par genre et par âge, en utilisant le
mot-clé level, indiquant qu’il faut grouper en utilisant l’index :
>>> d2012.groupby(level=["gender", "age"]).sum()
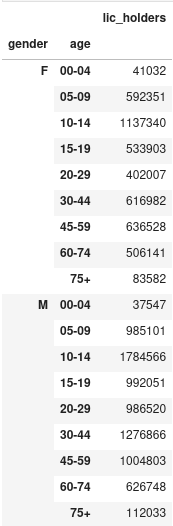
Dans quels départements la course camarguaise est-elle pratiquée ?
La course camarguaise est un sport traditionnel dans lequel les participants
tentent d'attraper des attributs primés fixés au frontal et aux cornes d'un
bœuf. Pour savoir dans quels départements ce sport est le plus pratiqué, nous
allons :
- Filtrer sur l’index pour n’avoir que les enregistrements correspondant à ce
sport (le code de la fédération est 215) ;
- Grouper par code et nom de département, et compter le nombre de licenciés ;
- Afficher les groupes triés par ordre décroissant de licenciés.
>>> d2012_camarg = d2012.xs(
215, level="fed_code"
) # Only keep the rows with index equal to 215 at level ``fed_code``
>>> d2012_camarg_depts = d2012_camarg.groupby(
["dep_code", "dep_name"]
).sum() # Group the data by department (only keep departments with non-null values)
>>> d2012_camarg_depts.sort_values(
by="lic_holders", ascending=False
) # Sort the data in decreasing order
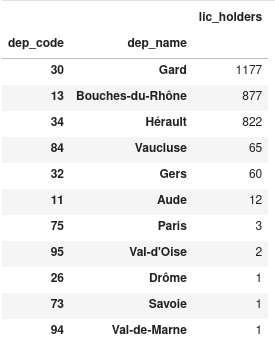
Sans trop de surprise, on observe que c’est le Gard (où est la Camargue), les
Bouches-du-Rhône, l’Hérault et le Vaucluse (départements qui entourent le Gard)
qui ont le plus de licenciés dans ce sport.
Quels sont les sports les plus pratiqués par les femmes ?
Nous allons :
- Sélectionner les enregistrements correspondant à
gender = 'F' ;
- Grouper par fédération et compter le nombre de licenciées ;
- Afficher les dix sports avec le plus de licenciées.
>>> d2012_females_top_10 = d2012.xs("F", level="gender")
.groupby(["fed_code", "fed_name"])
.sum()
.nlargest(10, "lic_holders")
>>> d2012_females_top_10

Pandas permet également de faire des graphiques. Par défaut c’est la
bibliothèque matplotlib qui est utilisée. Nous
pouvons par exemple utiliser un diagramme en bâtons pour afficher le top 10 des
sports pratiqués par les femmes :
>>> d2012_females_top_10.plot(
kind="bar",
legend=False,
xlabel="Sport federation",
ylabel="Number of license holders",
color="#CC0066",
title="Female sport license holders in 2012 (top 10)",
)
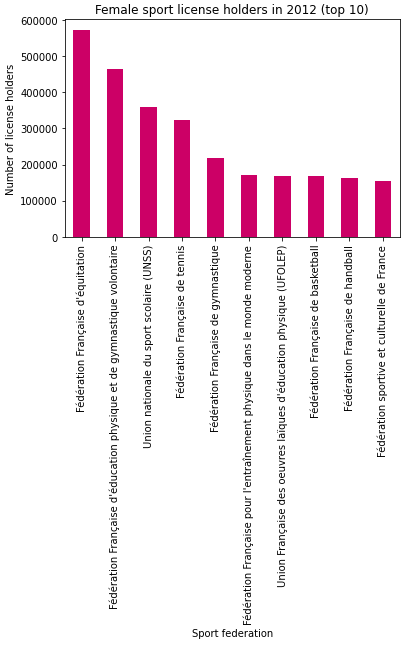
Charger les données pour toutes les années
Dans la section précédente, nous avons chargé uniquement les données de l’année
2012. Mais nous avons bien plus de données que cela. Nous allons donc charger
chaque fichier, puis renommer la colonne lic_holders en fonction de l’année en
cours. Nous aurons ainsi une DataFrame, avec en colonne le nombre de licenciés
par année, et en index les différents groupes.
Nous allons faire une liste years_dfs qui va contenir toutes les DataFrames,
une par année, puis nous allons simplement les concaténer. Cela donne donc :
>>> years_dfs = []
>>> for year in range(2012, 2019):
... fname = f"sport_license_holders_{year}.csv"
... yr_df = pd.read_csv(
... DATA_DIR / fname,
... dtype={"dep_code": str},
... index_col=["dep_code", "dep_name", "fed_code", "fed_name", "gender", "age"],
... )
... yr_df.rename(columns={"lic_holders": str(year)}, inplace=True)
... year_dfs.append(yr_df)
>>>
On concatène toutes les DataFrames, en fonction de l’index (axis=1) :
>>> data = pd.concat(years_df, axis=1)
>>> data
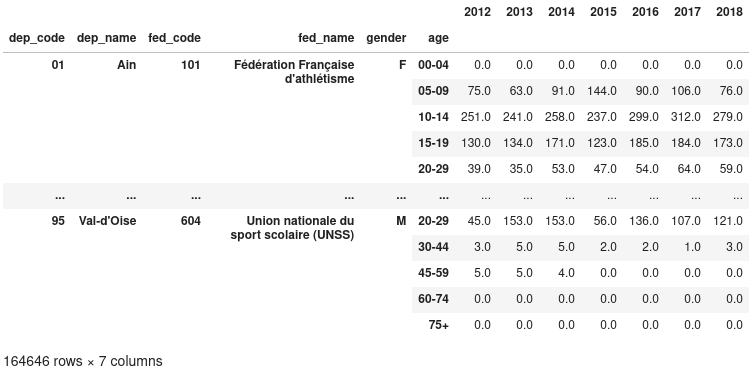
Nous avons ainsi une DataFrame avec plus de 1.6 million de lignes, et 7
colonnes.
On peut maintenant afficher, par exemple, les 10 sports les plus pratiqués en
fonction des années :
>>> data_sport = data.groupby(level=["fed_code", "fed_name"]).sum()
>>> data_sport.nlargest(10, "2012")
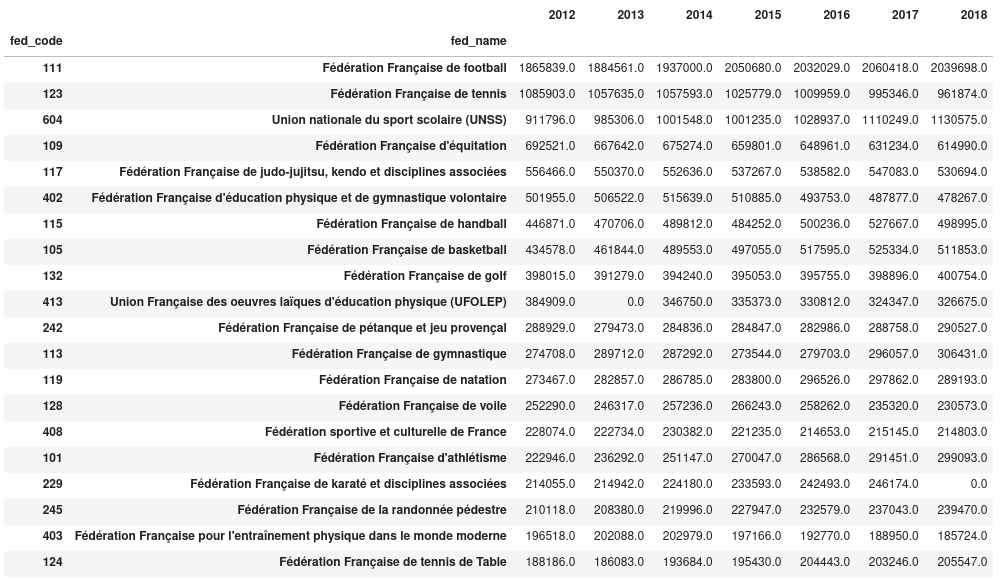
Nous avons ainsi le nombre de licenciés, par fédération et par année pour les
10 plus grosses fédérations de 2012. Le tri est effectué par rapport aux données
de 2012.
On notera qu’en 2018 il y a 0 licencié de Karaté. Cela est probablement une
erreur dans les données, ce qui peut arriver.
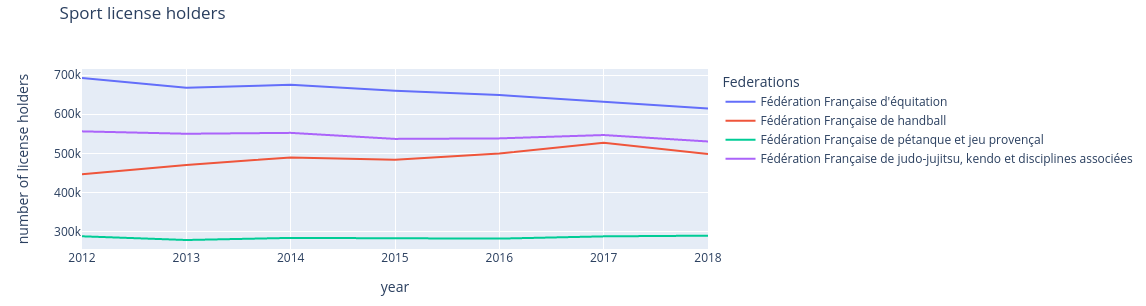
Tracer l'évolution du nombre de licenciés avec Plotly
Nous pouvons maintenant suivre l’évolution du nombre de licenciés dans certaines
disciplines. Nous sélectionnons les sports dont le code de fédération est 109,
115, 242, 117.
>>> sel_data_sports = data_sports.loc[
... [109, 115, 242, 117]
... ] # Select the rows whose value at the first level of the index (``fed_code``)
... # is one of the list items
>>> # Drop the first level of the index (``fed_code``)
>>> sel_data_sports = sel_data_sports.droplevel(0)
>>> # Will be used as the title of the legend
>>> sel_data_sports.index.name = "Federations"
>>> sel_data_sports.transpose().plot(
... title="Sport license holders", xlabel="year", ylabel="number of license holders"
...) # Transpose to have the years as the index (will be the X axis)
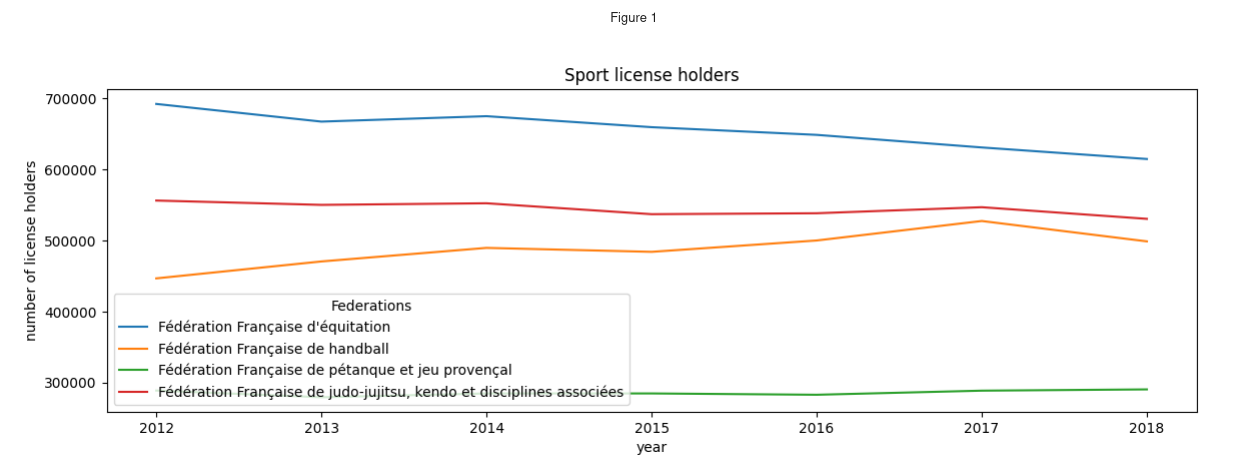
Comme nous le disions, par défaut Pandas utilise la bibliothèque matplotlib
pour générer les graphiques. La figure produite ici est statique, elle peut
facilement être insérée dans un rapport par exemple, mais cela présente des
difficultés lors de la phase d’exploration.
Depuis quelque temps maintenant, Pandas est compatible avec plusieurs
bibliothèques de visualisation. Il y a notamment
Plotly, qui permet de faire des graphiques
interactifs utilisables dans le navigateur web.
Pour utiliser Plotly, il est nécessaire de changer la bibliothèque utilisée
par défaut.
# Choose Plotly as the plotting back-end
# this has to be done only once, usually at the begining of the code
>>> pd.options.plotting.backend = "plotly"
Une fois Plotly configurée, nous pouvons retracer le graphique, comme
précédemment :
>>> fig = sel_data_sports.transpose().plot(title="Sport license holders")
>>> fig.update_layout(xaxis_title="year", yaxis_title="number of license holders")
>>> fig
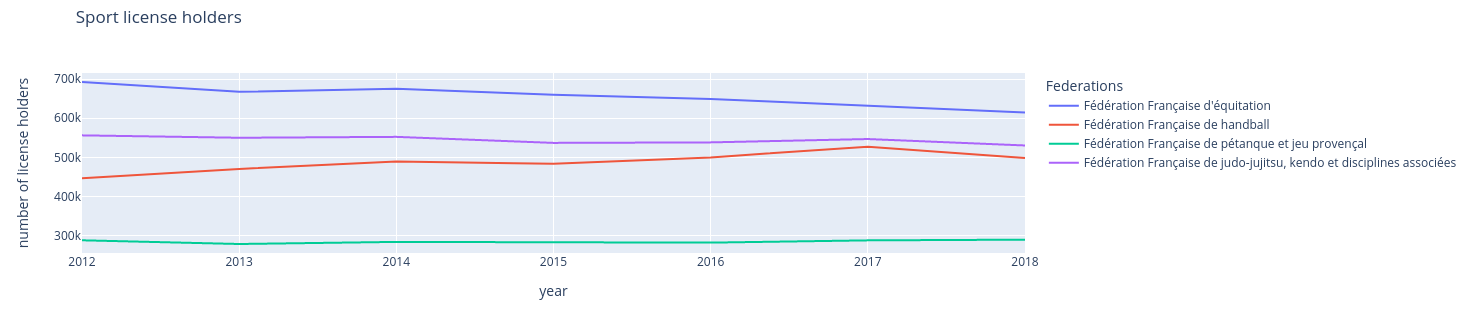
Dans un environnement Jupyter, la figure produite est celle-ci, et il est
possible de sélectionner/désélectionner les courbes à afficher :
Quelle est la prochaine étape ?
Nous avons dans ce premier article, chargé avec Pandas des données textuelles au
format CSV.
Nous avons vu comment et pourquoi utiliser un index multiple. Cela nous a permis
de calculer quelques statistiques simples sur des groupes d’individus. Nous
avons également produit des visualisations avec matplotlib et avec Plotly.
Dans le prochain article, nous utiliserons des widgets Jupyter pour manipuler
dynamiquement les données à afficher sur les graphiques.